

This is the second article from SQL Joins series, you can find the first article here. It talks about the basic concepts of joins and compares between different types of inner and outer joins. If you aren’t familiar with SQL Joins, kindly, read it first.
Now, we are going to discuss SQL Joins Performance and the usage of indexes with important tips on how to improve the performance of the queries that uses joins on huge tables. Don’t worry, we will avoid theoretical parts as possible (who loves equations anyway?!)
If you are interested in experiment’s technical details, check this repository [Attention: Geek stuff, Open with caution!]. If you are more concerned with the practical parts, you are in the right place.
Why is performance important?
At design-time, some databases’ designers neglect performance. At first, you only have limited number of records, why the worry?! This scenario causes very bad consequences. Let’s take an example:
A company is responsible for the system of roads’ tolls throughout a country. For 20 roads with an average of 250k car everyday, the system saves the details of each car’s passing time, fees, subscription, driver name, responsible employee and so on.
At first, the system will be great, but:
- What happens after 1 month? A lot of data
- What about 2 months? Huge data
- What about 6 months? We might be facing a Crisis!
This problem is a nightmare for any company:
- It might cause delay in results (Slow queries).
- After that, some requests suffers from timeout. In other words, results are never received (Queries takes more than timeout).
- Finally, the server itself might fail to operate any other requests. Yes, as you have read it: You might try to open any page or even another website on the same server to find that it is down!! This happens when RDBMS consumes much more resources (CPU, Memory or IO) than it should. A true nightmare for any IT Company.
This might be accepted for very complicated queries, but if your database design is not efficient, that might happen in very simple queries.
Complex cases need a database administrator, however, there are some easy tips that can solve this problem or at least limit its happening to much higher data.
Why to use indexes?
Can you imagine searching for a phone number written in a book without phone index? Horrible!
Database Indexes are used in a similar way. For example, if we want to get employees and related departments, we need to get each DepartmentID number in the Employee Table and search for it in the Department Table. What if department table is very large? We need to read it and search in all of it for each employee!! For a very simple query like this, high computation operations are considered a great failure for any database design and a start for the crisis. Luckily, indexes come to rescue!
Indexes improve the performance significantly for both search and join queries as we will show in the practical results, but this comes with a cost of increasing database modification time (inserting, deleting and some updating operations), however, this increase can be negligible in most cases unless these types of operations happen extensively.
As a rule of thumb: columns that are commonly used for searching or joining should be indexed in most cases.
Experiments & Benchmark
Used Database:
In the following experiments, we used the same database structure as shown in article 1:

We have populated it with fake data to be able to test the performance of different type of joins. Summary of the tables is shown in the following table:
| Table Name | Primary Key(s) | Foreign Key(s) | # of records |
| Department | ID | – | 6020 |
| Employee | SSN | DepartmentID | 1530802 |
| EmployeeBonus | – | EmployeeSSN | 1600184 |
Each experiment was conducted for 3 times and the average was calculated. For each experiment, we try the query in four cases:
- With indexes on both sides of the join (Primary Key and Foreign Key).
- With indexes on the Primary Key(s) only.
- With indexes on the Foreign Key(s) only.
- Without any indexes.
Advanced notes:
- Performance might change by changing the machine, operating system, running applications, model of processor, memory and etc.
- MySQL does some optimizations by default, so the behaviour might change by changing the RDBMS(MySQL) or the storage engine(innoDB).
- SQL_NO_CACHE: to make sure that MySQL doesn’t save any intermediate results in the cache, otherwise, results won’t be valid, however, it doesn’t have any effect on the results of the query. Never use it in production.
First Experiment (Inner Join):
In this experiment, we take inner join between 3 tables Employee, Department, EmployeeBonus. Query is written in two ways: (1)using the join condition inside where part of the statement. (2) using Inner Join.
Version 1 using Where (V1):
SELECT * FROM Department, Employee, EmployeeBonus WHERE Department.ID = Employee.DepartmentID AND Employee.SSN = EmployeeBonus.EmployeeSSN;
Version 2 using Inner Join (V2) :
SELECT * From Department INNER JOIN Employee ON Department.ID = Employee.DepartmentID INNER JOIN EmployeeBonus ON Employee.SSN = EmployeeBonus.EmployeeSSN;
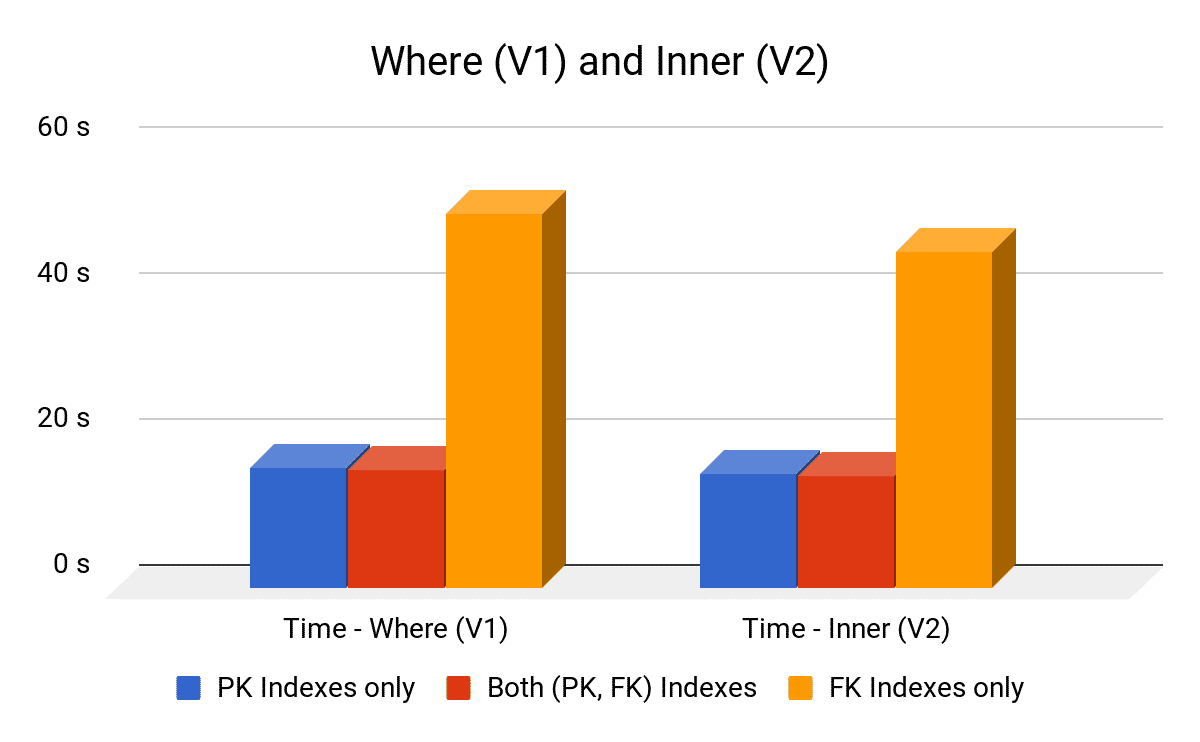
| Type of Used Indexes | Average (sec) | ||
| Where (V1) | Inner Join (V2) | ||
| Both PK and FK Indexes | 16.3 | 15.3 | |
| Only FK Indexes | 51.3 | 46 | |
| Only PK Indexes | 16.6 | 15.8 | |
| No Indexes | Didn’t Finish (> 2000 sec) | Didn’t Finish (> 2000 sec) | |
Results:
- Inner Join (V2) is slightly better than Where (V1). This might indicate that MySQL could use better optimization technique(s) in the case of Inner Join. [Note: other RDMBS can have the same performance for the two cases].
- Having indexes on both sides of the join has the best performance.
- Primary Keys’ indexes is more important than foreign keys’ indexes for inner joins, but any of them improves the performance dramatically.
- Removing indexes causes the performance to degrade significantly.
Experiment 2 (Left Outer Join)
In this experiment, we make left outer join between Employee and Department.
SELECT SQL_NO_CACHE Employee.SSN, Employee.Name as 'Employee Name', Department.Name as 'Department Name', Department.Email as 'Department Email' FROM Employee LEFT OUTER JOIN Department ON Department.ID = Employee.DepartmentID
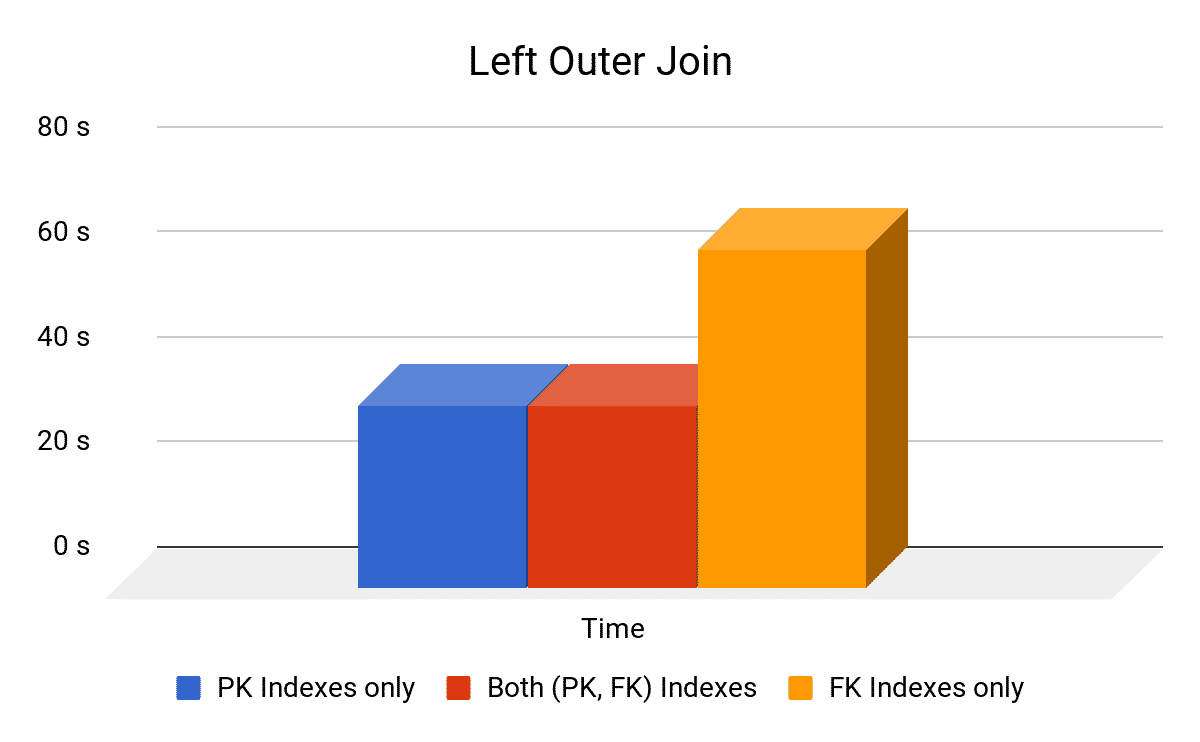
| Type of Used Indexes | Average (sec) | |
| Both PK and FK Indexes | 34.6 | |
| Only FK Indexes | 64.5 | |
| Only PK Indexes | 34.8 | |
| No Indexes | Didn’t Finish (> 2000 sec) | |
Third Experiment (Right Outer Join)
In this experiment, we make right outer join between Department and Employee.
SELECT SQL_NO_CACHE Employee.SSN, Employee.Name as 'Employee Name', Department.Name as 'Department Name', Department.Email as 'Department Email' FROM Employee RIGHT OUTER JOIN Department ON Department.ID = Employee.DepartmentID;
| Type of Used Indexes | Average(sec) | |
| Both PK and FK Indexes | 8.4 | |
| Only FK Indexes | 8.8 | |
| Only PK Indexes | 672.5 | |
| No Indexes | 677.9 | |
Results:
- Having indexes on both sides of the join has the best performance.
- Removing indexes causes the performance to degrade significantly.
- For Outer Joins, the important index depends on the field of the table that we need to search in. This technical explanation is very important for better understanding of how joins and indexes work:
Unlike Inner joins where only common rows are retrieved, In any Outer Join, there are Main Table from which all the rows are retrieved and a Related-Only Table from which only rows related to Main Table are needed. So, the only index that matter is the one in the Related-Only Table because it is the one that we will search in.
In experiment 2, All employees from Employee table(Main Table) are retrieved, but only related rows from Department (Related-Only Table) are needed, therefore, ID in the Department table is the important one. As, for each employee, we want to search for the related department, in other words, we need a quick way to search among all departments (Simply: an index).
In experiment 3, All departments of Department table (Main Table), but only related rows from Employee (Related-Only Table) are needed, therefore, DepartmentID in the Employee table is the important one, As, for each department, we want to search for all related.
In the next article, we discuss understanding of queries and the steps of execution and how to deal with slow queries on production environment from a PRACTICAL point of view with real scenarios and use-cases.











0 Comments